
1. Train, Test, Validation Data

Train Set
모델의 학습만을 위해서 사용
parameter나 feature 등을 수정하여
모델의 성능을 높이는 작업에 사용
Test Set
최종적으로 모델의 성능을 평가
실사용 되었을 때 모델이 얼마나 좋은 성능을 발휘 할 수 있을지 알아본다.
Validation Set
모델의 학습에 직접적으로 관여하지 않음
학습이 끝난 모델에 적용
최종적으로 모델을 fine tuning하는 데에 사용
딥러닝이든 머신러닝이든 훈련으로 학습된 모델의 성능을 확인 하려면 test를 해야한다.
테스트 데이터가 주어졌을때 훈련 데이터로 전부 사용하면 안된다.
일반적으로 7:3 혹은 8:2의 비율로 Training data와 Test data를 나눈다. 그 후 완성된 모델을 바탕으로 Test data를 사용하여 모델의 성능을 검증하게 된다.
2. 딥러닝의 분류 및 용어 정리

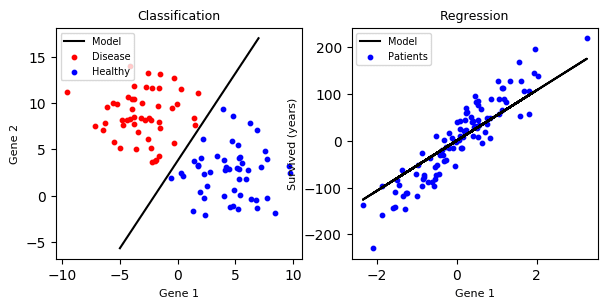
Supervised Learning(지도학습) 이란 머신러닝 에서 주어진 입력값 x가 있을때 결과값 y가 어떤 상관관계를 통해 나왔는지 예측하는 것이 목표인 것을 말한다. 이렇게 만들어진 모델은 주로 Regression(회귀분석)과 Classification(분류 분석) 문제를 해결하기 위해 사용된다. Regression 문제에서는 연속적인 값을 예측하고, Classification 문제에서는 여러 클래스 중 하나를 예측한다.
손실함수
손실 함수(Loss function)는 모델의 출력 값과 실제 값 사이의 차이를 계산하는 함수이다.
손실 함수는 모델이 학습을 통해 최적화되는 매개변수(가중치, 편향 등)를 찾기 위한 중요한 역할을 한다. 모델이 예측한 값이 실제 값과 차이가 크면 손실 함수의 값도 커지며, 반대로 차이가 작을수록 손실 함수의 값은 작아진다. 이를 통해 모델의 학습 과정에서 손실 함수를 최소화하는 방향으로 매개변수를 업데이트하며, 예측 성능을 향상시킨다.
손실 함수의 종류는 다양하며, 주로 회귀 문제와 분류 문제에 따라 다른 손실 함수를 사용한다. 회귀 문제에서는 주로 평균 제곱 오차(MSE, Mean Squared Error)나 평균 절대 오차(MAE, Mean Absolute Error)가 사용되고, 분류 문제에서는 주로 교차 엔트로피 손실(Cross-entropy loss)이 사용된다.
딥러닝에서는 주로 역전파(Backpropagation) 알고리즘을 사용하여 손실 함수를 최소화하는 방향으로 가중치를 조정한다. 이를 통해 모델이 예측 성능을 최적화하도록 한다.
평가지표
평가 지표는 모델의 성능을 측정하는 지표이다. 모델의 예측 결과와 실제 결과를 비하여 학습된 모델의 성능을 지표로 알려준다.
회귀 문제에서는 주로 평균 제곱 오차(MSE)나 평균 절대 오차(MAE)가 사용되고, 분류 문제에서는 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 스코어(F1-score) 등이 사용된다. 모델의 성능을 개선하고자 할 때는 이러한 평가 지표를 기반으로 모델을 수정하고 개선하는 것이 중요하다.
활성화 함수
활성화 함수는 인공 신경망의 노드에서 입력 신호의 총합을 출력으로 변환하는 함수이다. 이 함수는 비선형 함수를 사용하여 신경망이 복잡한 함수를 학습할 수 있도록 한다. 따라서, 활성화 함수의 종류와 파라미터를 조정함으로써 인공 신경망의 학습 및 성능 개선을 할 수 있다. 일반적으로 sigmoid, tanh, ReLU, LeakyReLU, softmax 등의 활성화 함수가 사용된다.
2.1 회귀 분석 (Regression)
Regression은 연속적인 값을 예측하는 문제에서 사용 된다. 예를 들어, 집의 크기, 위치, 방의 개수 등의 변수를 이용하여 집의 가격을 예측하는 문제가 해당된다. 최적화를 위해 주로 MSE(Mean Squared Error)나 MAE(Mean Absolute Error)와 같은 손실 함수를 사용한다.
2.1.1 회귀 분석 - 손실함수
MSE(Mean Squared Error) : 실제 값과 예측 값의 차이를 제곱하여 평균을 구한 값이다. 오차 값이 클수록 큰 값을 가지므로, 모델의 성능이 나쁜 것을 나타낸다.

MAE(Mean Absolute Error) : 실제 값과 예측 값의 차이를 절대값으로 구하여 평균을 구한 값이다. MAE는 오차 값의 크기만 중요하게 생각하는 지표로, 오차의 절대적인 크기를 파악할 때 사용한다.

RMSE(Root Mean Squared Error) : MSE의 제곱근으로, 실제 값과 예측 값의 차이를 제곱하여 평균을 구한 뒤 루트를 씌웠다. MSE와 달리 오차 값에 루트를 씌우므로, 오차의 크기와 방향성을 모두 반영할 수 있다.

2.1.1 회귀 분석 - 평가지표 - R2 score
R-squared는 선형 회귀 모델에 대한 적합도 측정값이다.선형 회귀 모델을 훈련한 후, 모델이 데이터에 얼마나 적합한지 확인하는 통계 방법 중 하나이다. r2 score는 0과 1사이의 값을 가지며 1에 가까울수록 선형회귀 모델이 데이터에 대하여 높은 연관성을 가지고 있다고 해석한다.
2.2 분류 분석(Classification)
Classification은 입력된 데이터를 여러 클래스 중 하나로 분류하는 문제에서 사용된다. 예를 들어, 이미지 분류 문제에서 입력된 이미지가 고양이, 강아지, 새 등의 동물 중 어떤 것인지 분류하는 문제가 이에 해당된다. 최적화를 위해 Cross-Entropy와 같은 손실 함수를 사용한다.
2.2.1 이진분류
이진분류는 참(True) 또는 거짓(False)을 판별하기 때문에 출력 값이 하나이다. 출력 값을 sigmoid 함수를 이용하여 0과 1로 가공한다. 로지스틱 회귀(Logistic Regression)는 이진분류모델을 분석하기 좋은 모델이다. 직선보다 적절한 곡선을 통해 분류를 한다.
2.2.2 다중분류
다중분류는 입력 값의 종류가 여러 개이기 때문에 출력 값도 여러 개이다. softmax 함수를 사용하여 0과 1사이의 값으로 가공한다.이를 one-hot encoding이라는 기법을 사용하여 나타낼 수 있다. 각 클래스가 정답일 확률을 0에서 부터 1사이의 값으로 정규화를 해준다.
원-핫 인코딩
- 라벨이 (0,0,1,0,0) , (0,1,0,0,0) 과 같이 one-hot encoding 된 형
태로 제공될 때 사용 가능
one-hot encoding
0 1 2
->
1 0 0
0 1 0
0 0 1
'TIL' 카테고리의 다른 글
| [AI] 딥러닝 CNN 모델 3주 13일차 (4) | 2023.05.11 |
|---|---|
| [AI] 딥러닝 최적화 알고리즘 3주 12일차 (3) | 2023.05.10 |
| [AI] 파이썬 딥러닝 기초 3주 10일차-4 (1) | 2023.05.09 |
| [AI] 딥러닝 공부를 위한 기초 파이썬 3주 10일차-3 (1) | 2023.05.08 |
| [AI] 딥러닝 공부를 위한 가상 환경 설정 3주 10일차-2 (0) | 2023.05.08 |